
SAT/ACT tests: why knowing algebra is good
SAT/ACT tests: why knowing algebra is good
A tale of two universities

After a few years in which almost all colleges dropped the use of SATs and ACTs in admissions, some prominent schools are going back to requiring them. Purdue, MIT, UT-Austin, Brown, Yale, and Dartmouth are some of the more noteworthy ones. Most others continue to not require the test, including the massive University of California system.
MIT has laid out their reasons for reinstating the requirement:
“Our research shows standardized tests help us better assess the academic preparedness of all applicants, and also help us identify socioeconomically disadvantaged students who lack access to advanced coursework or other enrichment opportunities that would otherwise demonstrate their readiness for MIT…. our ability to accurately predict student academic success at MIT is significantly improved by considering standardized testing — especially in mathematics — alongside other factors… not having SATs/ACT scores to consider tends to raise socioeconomic barriers to demonstrating readiness for our education, relative to having them”
The opposing rationale behind UC’s policy was given in 2020 by Berkeley professor Saul Geiser. Rather than explore a wide range of the literature, here I’ll just examine a deep logical flaw in Geiser’s reasoning, one shared by most opponents of using tests. Understanding the logical flaw will also clarify why schools such as MIT have found the tests to be useful, especially in finding good students from low-status backgrounds.
Here's the title and abstract of Geiser’s paper:
SAT/ACT SCORES, HIGH-SCHOOL GPA, AND THE PROBLEM OF OMITTED VARIABLE BIAS.
One of the major claims of the report of University of California’s Task Force on Standardized Testing is that SAT and ACT scores are superior to high-school grades in predicting how students will perform at UC. This finding has been widely reported in the news media and cited in several editorials favoring UC’s continued use of SAT/ACT scores in university admissions. But the claim is spurious, the statistical artifact of a classic methodological error: omitted variable bias. Compared to high-school grades, SAT/ACT scores are much more strongly correlated with student demographics like family income, parental education, and race/ethnicity. As a result, when researchers omit student demographics in their prediction models, the predictive value of the tests is artificially inflated. When student demographics are included in the model, the findings are reversed: High-school grades in college-preparatory courses are actually the stronger predictor of UC student outcomes. The Task Force should go back to the drawing board and provide the UC community with more realistic estimates of the true value-added by the tests.
Before proceeding, I’ll try to clarify the connection between those observations and our admissions policy choices. The question we would like to answer is, roughly, how to devise an admissions formula that admits students expected to do well but avoids giving an extra boost to students who already have a lot of advantages, i.e. high socioeconomic status (SES). For simplicity, let’s focus on linear models predicting first-year GPA. A purely predictive model might look like
aP*HSGPA+bP*SAT+cP*SES+dP*(other metrics) = predicted GPA.
The term involving other metrics leads to some complications (collider stratification bias) that need not concern us here, so let’s just drop it to focus the logic on the terms that Geiser discusses.
aP*HSGPA+bP*SAT+cP*SES = predicted GPA.
Here’s Geiser’s key table.
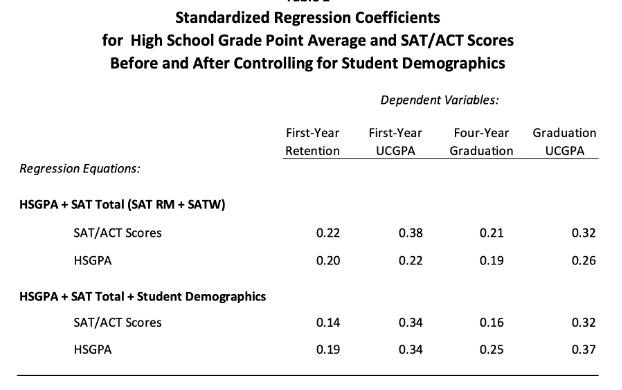
Geiser shows that, at least when trained on the set of students who were admitted to Cal and then enrolled, dropping the SES demographic term (i.e. setting cP to zero) and then allowing the other coefficients to adjust to still gave as accurate a prediction as they can in the more restricted model causes HSGPA’s aP to go down and SAT’s bP to go up.
At this point the logic takes a 180° turn. We want to use some sort of similar-looking formula to decide on who to admit. If we cared about nothing but picking the students most likely to succeed, and (for the sake of argument here) we weren’t worried about issues in extrapolating from differences in the previously selected group to the broader set of applicants, we could just use the best predictive formula, including an SES term that’s positive, i.e. gives explicit favoritism to rich kids, on top of whatever implicit advantages they have. That’s not what we want to do!
Instead, we want a similar-looking admissions formula but one that favors kids who haven’t had many advantages.
aA*HSGPA+bA*SAT+cA*SES = admissions score.
We still want to admit students who will do well, but we want one big change from the pure prediction formula. We want to use a negative SES coefficient cA rather than the positive one cP from the purely predictive model. When we make that substitution and then allow the other coefficients to adjust to make the admissions model as predictive as it can be with that constraint, how will the HSGPA and SAT coefficients aA and bA change from their relatives aP and bP?
Geiser’s data show how the coefficients change. Reducing the SES coefficient from positive to zero made the coefficient aP of HSGPA go down and the coefficient bP of SAT go up. Reducing the SES coefficient more, going past zero to negative, will just further reduce the HSGPA coefficient and further increase the SAT coefficient.
Thus, to the extent that Geiser’s argument has any implications for admissions procedures, it’s that putting more emphasis on admitting low SES students makes SATs more predictive of outcomes and HSGPA less predictive, compared to the default.
Here’s an example to help think about the issue. Say that you wanted to pick hefty students to be high school football linemen, but the only information you could use was their year in school and their height. Height by itself would be predictive of weight, as you could see even in a selected group of taller students. Year in school also would be predictive. Adding year in school to a predictive model would reduce the coefficient for height, because the two predictors are correlated. What would happen if you decided not to use the most predictive model to make your choices but instead to give preference to freshmen and sophomores, perhaps because they’d be on the team longer. Now your selection model has added a negative term for year in school. Instead of reducing height’s predictive coefficient, which a positive year-in-school term did, in this new model height’s coefficient goes up.
I’ve tried to figure out what Geiser’s reasoning was, helped by some responses from educators to the first version of this blog. It seems to go something like this. You can partially predict SAT from SES. Therefore SAT is unfair because it favors high SES. Therefore you shouldn’t use it. And you won’t lose much predictability because you can make a model that is fairly predictive without such a large SAT term- so long as you include the correlated SES. At this point the argument tends to break off. What’s omitted is the key caveat- you’d better not use that new model to make admissions decisions because it explicitly favors high SES applicants.
Although Geiser’s claim of “omitted variable bias” sounds sophisticated, his conclusion is the opposite of what his own data imply. Yes, the coefficient of one variable changes when another is included in a model, but which way it changes depends on the sign of how the other variable is included! This conclusion is not just a matter of simple math, math whose implications ought to have been evident to the expert policy-makers at Berkeley and elsewhere. It is also borne out by the real-world experience of colleges that dropped the test requirements, as described in the MIT statement. The MIT results are more or less predictable from Geiser’s data.
I’ve brushed over some issues in extrapolating from Geiser’s predictive models within sets of admitted students to predictive models within the set of potential applicants. It may be worth mentioning these.
The key question we want answered is how much useful information is lost by dropping a predictor, e.g. SAT. Its standardized coefficient in a model trained on the current cohort doesn’t directly give us that. If there are other strongly correlated predictors available then they can take up some of the slack when one is dropped. On the other hand, if there are other variables used in admissions but omitted from the model collider stratification bias can lead us to underestimate how much would be lost by dropping a predictor in the model.
Predictions of some outcomes become a bit fuzzy when disparate outcomes get lumped together under one name. A predictor like the math SAT would be expected to be much better at predicting graduation in physics than in education. Lumping both types of degrees together obscures the factors needed to predict success in e.g. physis. In order to minimize that issue studies often focus on predictions of first-year GPA, since first year courses are less radically different in difficulty for different majors than are upper-level courses. Ideally, one would want to compare outcomes on some shared measure. Coincidentally, I had a chance to help out on a research project comparing in-person to online delivery of statistics lectures, where outcomes could be compared on tests that all the students shared, rather than different tests for students admitted with different prior test scores etc. Since the enrollment couldn’t be randomized, we had to look for as many student attributes as we could find in order to adjust the comparison for differences between students in the two treatment groups. We found “ACTmath is the most significant covariate”, i.e. it was easily the best predictor. It would be good to see more data on predictors of closely matched outcome measures.
Chetty, Deming, and Friedman have taken a more serious look at what the effects of changing admissions procedures would be, using modern causal inference methods rather than vague impressions from correlations. They “conclude that there are a substantial number of low- and middle-income students with strong potential outcomes – students with high academic ratings or simply high SAT/ACT scores – who apply to Ivy-Plus colleges but are presently not admitted. Admitting more of these students could allow colleges to diversify their student body while improving class quality, as measured by the set of outcomes we analyze here.” There is not quite so much room for improvement at the big state schools, because they use less of the special non-academic criteria that give a boost to high-SES applicants than do the Ivy-Plus colleges. Nevertheless, their analysis makes it clear that using test scores is a key part of diversifying SES backgrounds while finding students who will do well in college and then in subsequent work.
It's encouraging that so many good schools are responding to data and once again making some use of the best of the mediocre predictors of how well students will handle college courses, especially challenging STEM courses. It’s depressing that many leaders in education not only ignore the data but construct fancy-sounding excuses for doing so, covering up what amount to incorrect answers to high-school level word problems with sophisticated phrases learned in college.
Testing Candidates
Standardized test results are valuable to reduce socioeconomic status (SES) influence in college admissions decisions.
Standardized tests could also be valuable to reduce SES influence in choosing the best candidates for public offices, such as Congress. Do they understand important topics (economics, history, …) ? Let’s make standardized tests available for voluntary testing of candidates and release the results. Then we can see who is brave enough to be tested and who understands the important issues. This information could help avoid election of politicians who are charming, but inept.